
Hi everyone,
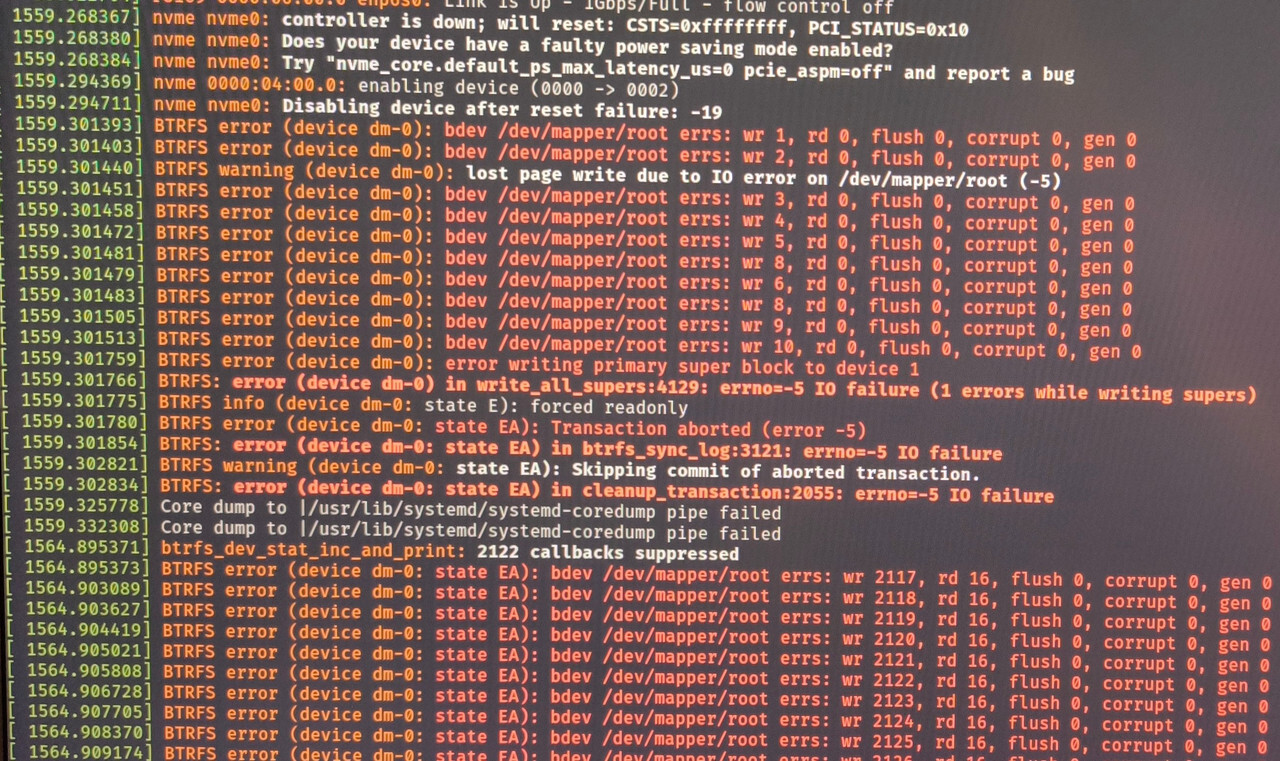
I have been experiencing some weird problems lately, starting with the OS becoming unresponsive “randomly”. After reinstalling multiple times (different filesystems, tried XFS and BTRFS, different nvme slots with different nvme drives, same results) I have narrowed it down to heavy IO operations on the nvme drive. Most of the time, I can’t even pull up dmesg, and force shutdown, as ZSH gives an Input/Output error no matter the command. A couple of times I was lucky enough for the system to stay somewhat responsive, so that I could pull up dmesg.
It gives a controller is down, resetting message, which I’ve seen on archwiki for some older Kingston and Samsung nvmes, and gives Kernel parameters to try (didn’t help much, they pretty much disable aspm on pcie).
What did help a bit was reverting a recent bios upgrade on my MSI Z490 Tomahawk, causing the system to not crash immediately with heavy I/O, but rather mount as ro, but the issue still persists. I have additionally run memtest86 for 8 passes, no issues there.
I have tried running the lts Kernel, but this didn’t help. The strange thing is, this error does not happen on Windows 11.
Has anyone experienced this before, and can give some pointers on what to try next? I’m at my wits end here. EDIT: When this issue first appeared, I assumed the Kioxia drive was defective, which the manufacturer replaced after. This issue still happens with the new replacement drive too, as well as the Samsung drive. I thus assume, that neither drives are defective (smartctl also seems to think so)
Here are hardware and software details:
- Arch with latest Zen Kernel, 6.7.4, happened with other, older kernels too though, tried regular, lts and zen
- BTRFS on LUKS
- i9-10850k
- MSI z490 Tomahawk
- GSkill 3200 MHz RAM, 32GB, DDR4
- Samsung 970 Evo 1TB & Kioxia Exceria G2 1TB (tested both drives, in both slots each, over multiple installs)
- Vega 56 GPU
- Be quiet Straight Power 11 750W PSU
You must log in or register to comment.
Could you post your full (relevant/redacted) journalct logs prior to the crash? Would be interesting to see if there was something else going on at the time which could’ve triggered it.
journalctl -b -1will show all messages from the previous boot.Also, what’s your
/etc/fstablike? Just wondering whether changing any of the mount options could help (egcommit=,discardetc).Finally, have you checked
fwupdmgrfor firmware updates for your NVMe controller/drives? You should also check the respective manufacturer’s website, since not everyone publishes their firmware to the LVFS.Also, I found this thread where someone with a similar issue solved it by swapping out their PSU, so might be worth swapping it out if you can and see if it makes a difference.
Thanks for helping! Unfortunately, journalctl doesn’t show anything really. Trying to run
journalctl -b -1showsSpecifying boot ID or boot offset has no effect, no persistent journal was found., which is a bit strange. It used to just show the previous journal (I couldn’t find anything suspicious though), but no error related stuff, I assume due to the filesystem being mounted ro right after the crash, it wasn’t able to write anything to the journal unfortunately. EDIT: The only errors I have seen in dmesg were related to a Broadcom PCIe wireless card (which I have removed now for further testing): brcmfmac: brcmf_c_process_clm_blob: no clm_blob available (err=-2), device may have limited channels available. Although I have read that this is a common message for this type of card (broadcom 43602) and it’s nothing to worry about.The fstab looks like this (redacted UUIDs for clearer formatting):
/ btrfs rw,relatime,ssd,space_cache=v2,subvolid=256,subvol=/@ 0 0 /home btrfs rw,relatime,ssd,space_cache=v2,subvolid=257,subvol=/ 0 0 /.snapshots btrfs rw,relatime,ssd,space_cache=v2,subvolid=258,subvol=/@.snapshots 0 0 /opt btrfs rw,relatime,ssd,space_cache=v2,subvolid=259,subvol=/ 0 0 /root btrfs rw,relatime,ssd,space_cache=v2,subvolid=260,subvol=/ 0 0 /srv btrfs rw,relatime,ssd,space_cache=v2,subvolid=261,subvol=/ 0 0 /var btrfs rw,relatime,ssd,space_cache=v2,subvolid=262,subvol=/ 0 0 /var/lib/portables btrfs rw,relatime,ssd,space_cache=v2,subvolid=263,subvol=//lib/portables 0 0 /var/lib/machines btrfs rw,relatime,ssd,space_cache=v2,subvolid=264,subvol=//lib/machines 0 0 /var/lib/libvirt/images btrfs rw,relatime,ssd,space_cache=v2,subvolid=265,subvol=//lib/libvirt/images 0 0 /var/spool btrfs rw,relatime,ssd,space_cache=v2,subvolid=266,subvol=//spool 0 0 /var/cache/pacman/pkg btrfs rw,relatime,ssd,space_cache=v2,subvolid=267,subvol=//cache/pacman/pkg 0 0 /var/log btrfs rw,relatime,ssd,space_cache=v2,subvolid=268,subvol=//log 0 0 /var/tmp btrfs rw,relatime,ssd,space_cache=v2,subvolid=269,subvol=//tmp 0 0 /boot vfat rw,relatime,fmask=0022,dmask=0022,codepage=437,iocharset=ascii,shortname=mixed,utf8,errors=remount-ro 0 2Regarding firmware updates, I have tried running fwupd, but no updates are available. Tried both samsung’s and kioxia’s update tool on Windows too, both drives are running the latest firmware.
Thanks for the detailed reply, I will check the reddit post out. Although my PSU should be powerful enough, and it is relatively recent (3-4 years, so I assume the deterioration should not be that bad)
ssds getting not enough power? i’d test it with different PSU, i had a problem with my ssd failing and changing PSU worked, apparently 3.3VDC rail is routed on the motherboards without any conversion straight to m.2/pcie devices
Unfortunately I don’t have a spare PSU, but I might try to measure the 3.3 volt rail with a multimeter (don’t own an oscilloscope unfortunately) while under load and see what happens
Do you have a spare set up where you can boot up from that same SSD? Literally any laptop would work plug and play and that would rule out the possibility of it being the motherboard on the OP.
Yeah, an oscilloscope would be handy in hunting spikes, it’s a bit harder with a standard multimeter, you sure you don’t know anyone with a spare PSU to borrow?
you could also try one of those USB to m.2 and see if that works
I had a similar issue years ago in around 2018 with a Samsung nvme SSD that came stock from Dell with an XPS, me and another guy from a thread on Reddit ended up emailing with a guy from canonical and dell. The troubleshooting email chain went on for almost a year after which I just switched to a wd black and haven’t had the issue since (still using the same wd black to this day)
Anyhow, they ended up moving the discussion to launchpad, maybe perusing there might help you troubleshoot: https://bugs.launchpad.net/ubuntu/+source/linux/+bug/1746340
The only thing I can think of is to try the drives in a different system and see how they behave (same OS and configuration).
If they behave the same then that rules out everything except the drives themselves and the OS.
Considering how you mentioned the behavior is better in Windows, it sounds like a software issue, but you never know until you try.
The other way to look at it is to stick the drives into a usb enclosure. That gets you away from the PC’s 3v3 rail. If you then hang the drive enclosure off of a powered hub/dock, you are definitely way outside of the PC’s power supply problems.
Here’s one that I have, hopefully it’s still made halfway good. https://www.amazon.com/gp/product/B08G14NBCS/
Not a bad idea actually, totally didn’t think about that.
Unfortunately I have no other system at hand at the moment that’s able to accept nvme drives :( I could try using windows for a couple of days see whether the issue is really linux-related, but I am trying to avoid that lol
Maybe phone a friend?
Maybe even a PCIe pass through to a VM could do the trick if you’re desparate lol (with Linux living in a separate drive)
Orrrr maybe even try FreeBSD… (or mac OS, but eww gross don’t test that)
What brand is Kioxia?
it’s a sub brand of Toshiba, so not some unknown shit, very respected brand i’d say
Yeah I did a bit of reading. I was about to blame the no-name Chinese storage! There’s so much garbage nvme stuff floating around lately.
there is so much garbage flash in general lately
yeah the entire market segment is riddled with cheap chinese shit to downright fraudulent devices.
Have you tried a different motherboard?
If you have swap enabled, disabling it may prevent your Linux from freezing. You can try it out with
swapoff -a.Thanks, will try. Although I don’t think this’ll be an issue, as I have more than enough memory, swap should only be used for hibernation
Which of the drives does this happen with? Or does it happen with both?
Happens with both drives, I have tried each possible permutation (Samsung in slot 1 and 2, kioxia in slot 1 and 2, and even only installing one drive at a time)
Boot a live ISO with the flags recommended in the kernel message and do some tests on the bare drives. That way you won’t have the filesystem and subsequently the rest of the system giving out on you while you’re debugging.
Boot a live ISO with the flags recommended in the kernel message and do some tests on the bare drives. That way you won’t have the filesystem and subsequently the rest of the system giving out on you while you’re debugging.
Which tests are you referring to exactly? I have read about badblocks for example, and it not being much use for ssds in general, due to their automatic bad-block-remapping, so they remain invisible to the OS as all remapping happens in the drive’s controller. Smart values look great for both drives, about 20TBW on the Samsung drive, and a lot less on the Kioxia drive.
I’d start by generating some synthetic workloads such as writing some sequential data to it and then reading it back a few times.
badblocksconcerns partial failure of the device where (usually) just a few blocks misbehave while the rest remains accessible. The failure mode seen here is that the entire drive becomes inaccessible and it’s likely not due to the drive itself but how it’s connected.If synthetic loads fail to reproduce the error, I’d put a filesystem on it and copy over some real data perhaps. Put on some load that mimics a real system somehow to try and get it to fail without the OS actually being ran off the drive.
Thanks, I’ll try that. I loaded the drive using dd a couple of times, and that did bring the system down a couple of times. I was writing to the filesystem though, while the system was booted
Did you boot with the kernel flags from the log?
Could you show the dmesg from the point onwards when the drive dropped out?
I did, yes, but no avail. The dmesg output I posted is after the drive was mounted as ro, and is the best i could get. After some time, the system stops responding completely
Are both drives fully encrypted with LUKS? Is trim enabled in both crypttab and fstab?
Both drives were encrypted (Samsung as root drive, encrypted except for the efi partition, and kioxia fully encrypted and mounted via crypttab and a key file residing on the encrypted Samsung partition for automatic unlock), although now as I have been reinstalling quite often, and couldn’t be bothered to set up the encryption for the second drive so it stays unused atm. Trim is enabled via a kernel parameter, but not in the fstab directly anymore (as I’m running BTRFS now, and from what I’ve gathered passing the ssd option to BTRFS is enough to enable trim, verified with lsblk --discard)
This is probably a strange question, but did you memtest86 your memory already?
I did, yes. One of the first ideas I got.
I see it now, dammit sorry
Did you even read the post?
I’m sorry, did I overlook the memory tested part? I don’t see it?
Edit: I see it now, sorry
From what you have commented I would lean toward either a power issue or a pcie signaling issue. Are you running any kind of overclock? You could try underclocking and see if that stabilizes it as it won’t draw as much power.
Have you tried booting from a live image? I’d try downloading something with a live option like Ubuntu to a flash drive, and then trying to mount the drive from that. Anecdotally I had massive issues with Manjaro a while back where it would “lose” access to entire usb bays on the motherboard that didn’t happen in Debian etc.




