

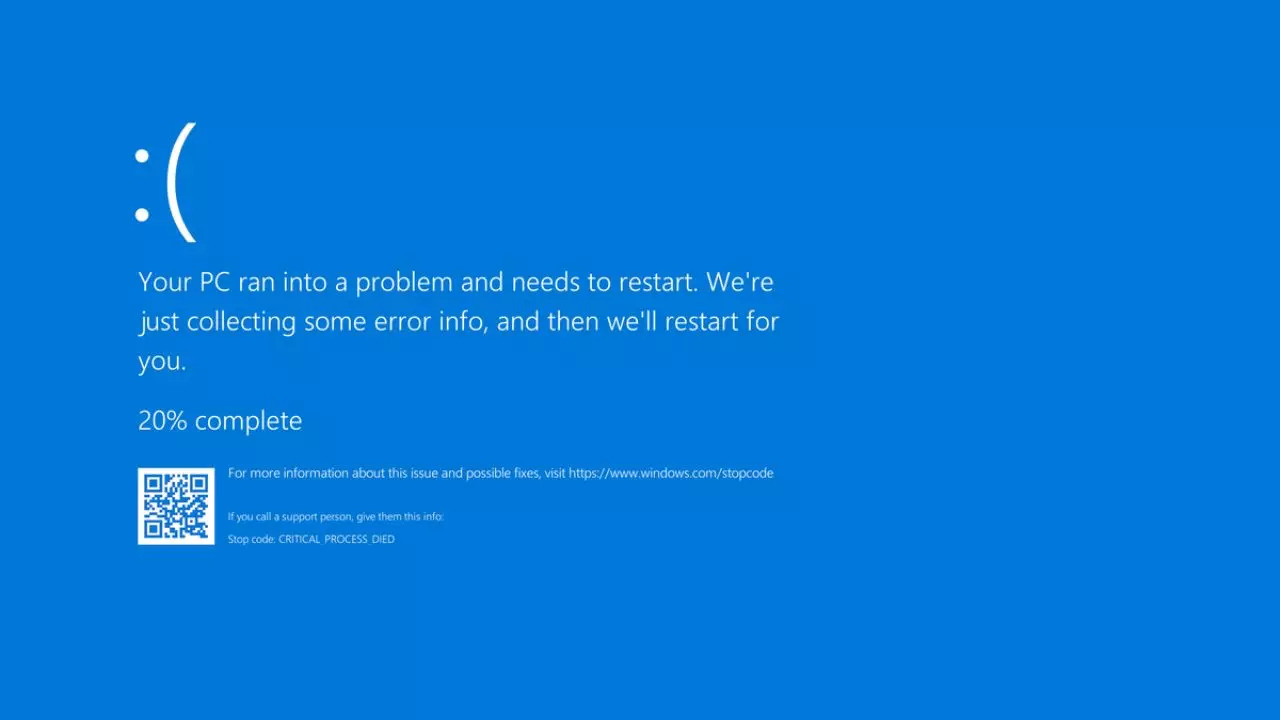
This isn’t a gloat post. In fact, I was completely oblivious to this massive outage until I tried to check my bank balance and it wouldn’t log in.
Apparently Visa Paywave, banks, some TV networks, EFTPOS, etc. have gone down. Flights have had to be cancelled as some airlines systems have also gone down. Gas stations and public transport systems inoperable. As well as numerous Windows systems and Microsoft services affected. (At least according to one of my local MSMs.)
Seems insane to me that one company’s messed up update could cause so much global disruption and so many systems gone down :/ This is exactly why centralisation of services and large corporations gobbling up smaller companies and becoming behemoth services is so dangerous.
The annoying aspect from somebody with decades of IT experience is - what should happen is that crowdstrike gets sued into oblivion, and people responsible for buying that shit should have an epihpany and properly look at how they are doing their infra.
But will happen is that they’ll just buy a new crwodstrike product that promises to mitigate the fallout of them fucking up again.
decades of IT experience
Do any changes - especially upgrades - on local test environments before applying them in production?
The scary bit is what most in the industry already know: critical systems are held on with duct tape and maintained by juniors 'cos they’re the cheapest Big Money can find. And even if not, There’s no time. or It’s too expensive. are probably the most common answers a PowerPoint manager will give to a serious technical issue being raised.
The Earth will keep turning.
some years back I was the ‘Head’ of systems stuff at a national telco that provided the national telco infra. Part of my job was to manage the national systems upgrades. I had the stop/go decision to deploy, and indeed pushed the ‘enter’ button to do it. I was a complete PowerPoint Manager and had no clue what I was doing, it was total Accidental Empires, and I should not have been there. Luckily I got away with it for a few years. It was horrifically stressful and not the way to mitigate national risk. I feel for the CrowdStrike engineers. I wonder if the latest embargo on Russian oil sales is in anyway connected?
I wonder if the latest embargo on Russian oil sales is in anyway connected?
Doubt it, but it’s ironic that this happens shortly after Kaspersky gets banned.
Unfortunately falcon self updates. And it will not work properly if you don’t let it do it.
Also add “customer has rejected the maintenance window” to your list.
Turns out it doesn’t work properly if you do let it
Well, “don’t have self-upgrading shit on your production environment” also applies.
As in “if you brought something like this, there’s a problem with you”.
Not OP. But that is how it used to be done. Issue is the attacks we have seen over the years. IE ransom attacks etc. Have made corps feel they needf to fixed and update instantly to avoid attacks. So they depend on the corp they pay for the software to test roll out.
Autoupdate is a 2 edged sword. Without it, attackers etc will take advantage of delays. With it. Well today.
I’d wager most ransomware relies on old vulnerabilities. Yes, keep your software updated but you don’t need the latest and greatest delivered right to production without any kind of test first.
Very much so. But the vulnerabilities do not tend to be discovered (by developers) until an attack happens. And auto updates are generally how the spread of attacks are limited.
Open source can help slightly. Due to both good and bad actors unrelated to development seeing the code. So it is more common for alerts to hit before attacks. But far from a fix all.
But generally, time between discovery and fix is a worry for big corps. So why auto updates have been accepted with less manual intervention than was common in the past.
I would add that a lot of attacks are done after a fix has been released - ie compare the previous release with the patch and bingo - there’s the vulnerability.
But agree, patching should happen regularly, just with a few days delay after the supplier release it.
I get the sentiment but defense in depth is a methodology to live by in IT and auto updating via the Internet is not a good risk to take in general. For example, should Crowdstrike just disappear one day, your entire infrastructure shouldn’t be at enormous risk nor should critical services. Even if it’s your anti-virus, a virus or ransomware shouldn’t be able to easily propagate through the enterprise. If it did, then it is doubtful something like Crowdstrike is going to be able to update and suddenly reverse course. If it can then you’re just lucky that the ransomware that made it through didn’t do anything in defense of itself (disconnecting from the network, blocking CIDRs like Crowdsource’s update servers, blocking processes, whatever) and frankly you can still update those clients anyway from your own AV update server which is a product you’d be using if you aren’t allowing updates from the Internet in order to roll them out in dev first, phasing and/or schedules from your own infrastructure.
Crowdstrike is just another lesson in that.
I isn’t even a Linux vs Windows thing but a competent at your job vs don’t know what the fuck you are doing thing. Critical systems are immutable and isolated or as close as reasonably possible. They don’t do live updates of third party software and certainly not software that is running privileged and can crash the operating system.
I couldn’t face working in corporate IT with this sort of bullshit going on.
This is just like “what not to do in IT/dev/tech 101” right here. Every since I’ve been in the industry for literally decades at this point I was always told, even when in school, “Never test in production, never roll anything out to production on a Friday, if you’re unsure have someone senior code review” of which, Crowdstrike, failed to do all of the above. Even the most junior of junior devs should know better. So the fact that this update was allowed go through…I mean blame the juniors, the seniors, the PM’s, the CTO’s, everyone. If your shit is so critical that a couple bad lines of poorly written code (which apparently is what it was) can cripple the majority of the world…yeah crowdstrike is done.
It’s incredible how an issue of this magnitude didn’t get discovered before they shipped it. It’s not exactly an issue that happens in some niche cases. It’s happening on all Windows computers!
This can only happen if they didn’t test their product at all before releasing to production. Or worse: maybe they did test, got the error, and they just “eh, it’s probably just something wrong with test systems”, and then shipped anyway.
This is just stupid.
Can you imagine being the person that hit that button today? Jesus.
It’s also a “don’t allow third party proprietary shit into your kernel” issue. If the driver was open source it would actually go through a public code review and the issue would be more likely to get caught. Even if it did slip through people would publically have a fix by now with all the eyes on the code. It also wouldn’t get pushed to everyone simultaneously under the control of a single company, it would get tested and packaged by distributions before making it to end users.
It’s actually a “test things first and have a proper change control process” thing. Doesn’t matter if it’s open source, closed source scummy bullshit or even coded by God: you always test it first before hitting deploy.
deleted by creator
One shop I was at had a manual process going with cash only purchases.
That blew up when I ordered 3 things and the ‘cashier’ didn’t know how to add them together. They didn’t have calculator on Windows available🤣
I told them the total and change to give me, but lent them the calculator on my phone so they could verify for themselves 🤣
It’s not that clear cut a problem. There seems to be two elements; the kernel driver had a memory safety bug; and a definitions file was deployed incorrectly, triggering the bug. The kernel driver definitely deserves a lot of scrutiny and static analysis should have told them this bug existed. The live updates are a bit different since this is a real-time response system. If malware starts actively exploiting a software vulnerability, they can’t wait for distribution maintainers to package their mitigation - they have to be deployed ASAP. They certainly should roll-out definitions progressively and monitor for anything anomalous but it has to be quick or the malware could beat them to it.
This is more a code safety issue than CI/CD strategy. The bug was in the driver all along, but it had never been triggered before so it passed the tests and got rolled out to everyone. Critical code like this ought to be written in memory safe languages like Rust.
I couldn’t face working in corporate IT with this sort of bullshit going on.
im taking you don’t work in IT anymore then?
There are state and government IT departments.
More generally: delegate anything critical to a 3rd party and you’ve just put your business at the mercy of the quality (or lack thereof) of their own business processes which you do not control, which is especially dangerous in the current era of “cheapest as possible” hiring practices.
Having been in IT for almost 3 decades, a lesson I have learned long ago and which I’ve also been applying to my own things (such as having my own domain for my own e-mail address rather than using something like Google) was that you should avoid as much as possible to have your mission critical or hard to replace stuff dependent on a 3rd Party, especially if the dependency is Live (i.e. activelly connected rather than just buying and installing their software).
I’ve managed to avoid quite a lot of the recent enshittification exactly because I’ve been playing it safe in this domain for 2 decades.
deleted by creator
Our group got hit with this today. We don’t have a choice. If you want to run Windows, you have to install this software.
It’s why stuff like this is so crippling. Individual organizations within companies have to follow corporate mandates, even if they don’t agree.
So it’s Linux vs Windows
No it’s Crowdstrike… we’re just seeing an issue with their Windows software, not their Linux software.
That being said Microsoft still did hire crowd strike and give them the keys to release an update like this.
End result still is windows having more issues than linux
Huh? Crowdstrike is an antivirus product, you’re only affected if you bought and installed it on your Windows devices. Crowdstrike also had issues with their Linux version a few weeks ago, but that one was thankfully less severe.
Didn’t Crowdstrike have a bad update to Debian systems back in April this year that caused a lot of problems? I don’t think it was a big thing since not as many companies are using Crowdstrike on Debian.
Sounds like the issue here is Crowdstrike and not Windows.
They didn’t even bother to do a gradual rollout, like even small apps do.
The level of company-wide incompetence is astounding, but considering how organizations work and disregard technical people’s concerns, I’m never surprised when these things happen. It’s a social problem more than a technical one.
They didn’t even bother to test their stuff, must have pushed to prod
(Technically, test in prod)
Everyone has a test environment
Some are lucky enough to also have a separate production environment
A crowdstrike update killed a bunch of our Linux VMs that had a newer kernel a month or so ago.
*crowdstrike
While I don’t totally disagree with you, this has mostly nothing to do with Windows and everything to do with a piece of corporate spyware garbage that some IT Manager decided to install. If tools like that existed for Linux, doing what they do to to the OS, trust me, we would be seeing kernel panics as well.
Hate to break it to you, but CrowdStrike falcon is used on Linux too…
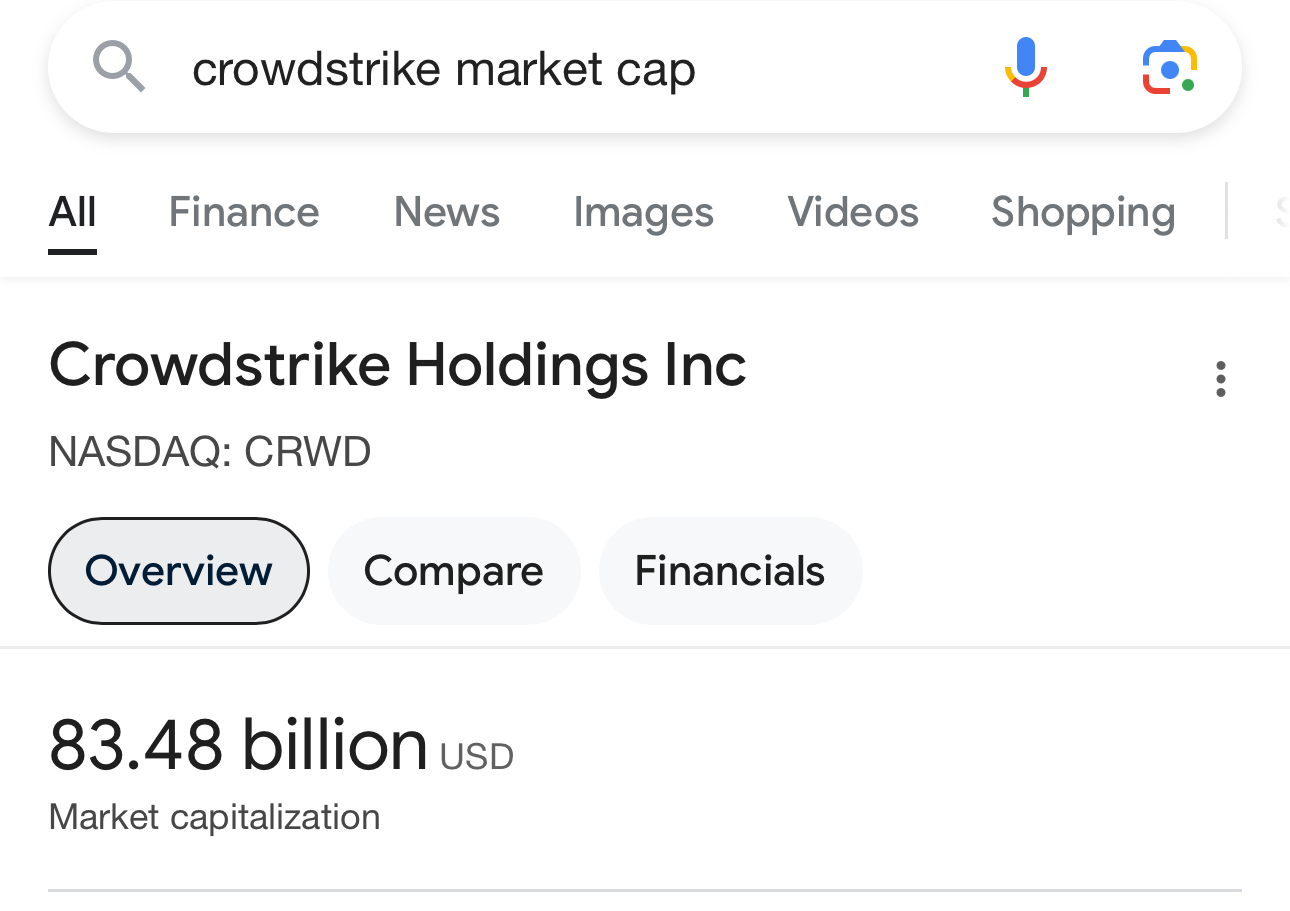
And if it was a kernel-level driver that failed, Linux machines would fail to boot too. The amount of people seeing this and saying “MS Bad,” (which is true, but has nothing to do with this) instead of “how does an 83 billion dollar IT security firm push an update this fucked” is hilarious
Falcon uses eBPF on Linux nowadays. It’s still an irritating piece of software, but it no make your boxen fail to boot.
edit: well, this is a bad take. I should avoid commenting on shit when I’m sleep deprived and filled with meeting dread.
deleted by creator
It was panicking RHEL 9.4 boxes a month ago.
Were you using the kernel module? We’re using Flatcar which doesn’t support their .ko, and we haven’t been getting panics on any of our machines (of which there are many).
Nah it was specifically related to their usage of BPF with the Red Hat kernel, since fixed by Red Hat. Symptom was, you update your system and then it panics. Still usable if you selected a previous kernel at boot though.
You’re asking the wrong question: why does a security nightmare need a 90 billion dollar company to unfuck it?
What’s your solution to cyberattacks?
Linux in the hands of professionals. There’s a reason IIS isn’t used anymore.
That doesn’t solve anything. Linux is also subject to cyberattacks.
And Macs, we have it on all three OSs. But only Windows was affected by this.
Hate to break it to you, but most IT Managers don’t care about crowdstrike: they’re forced to choose some kind of EDR to complete audits. But yes things like crowdstrike, huntress, sentinelone, even Microsoft Defender all run on Linux too.
Yeah, you’re right.
I wouldn’t call Crowdstrike a corporate spyware garbage. I work as a Red Teamer in cybersecurity, and EDRs are bane of my existence - they are useful, and pretty good at what they do. In the last few years, I’m struggling more and more to with engagements we do, because EDRs just get in the way and catch a lot of what would pass undetected a month ago. Staying on top of them with our tooling is getting more and more difficult, and I would call that a good thing.
I’ve recently tested a company without EDR, and boy was it a treat. Not defending Crowdstrike, to call that a major fuckup is great understatement, but calling it “corporate spyware garbage” feels a little bit unfair - EDRs do make a difference, and this wasn’t an issue with their product in itself, but with irresponsibility of their patch management.
Fair enough.
Still this fiasco proved once again that the biggest thread to IT sometimes is on the inside. At the end of the day a bunch of people decided to buy Crowdstrike and got screwed over. Some of them actually had good reason to use a product like that, others it was just paranoia and FOMO.
How is it not a window problem?
Why should it be? A faulty software update from a 3rd party crashes the operating system. The exact same thing could happen to Linux hosts as well with how much access those IPSec programms usually get.
But that patch is for windows, not Linux. Not a hypothetical, this is happening.
Your fixated on the wrong part of the story. Synchronized supply chain update takes out global infrastructure isn’t a windows problem, this happens on linux too!
Just because a drunk driver crashes their BMW into a school doesn’t mean drunk driving is only a BMW vehicle problem.
I love how quickly everyone has forgotten about that xz attack.
I use and love Linux and have for over two decades now, but I’m not going to sit here and claim that something similar to the current Windows issue can’t happen to Linux.
xz attack
That has nothing to do with this. That was a security vulnerability, solved in record time, blame where it was due, and patched in hours.
You’re missing the point. That compromised xz made it into some production distributions. The point here is that shit can happen to Linux, too.
If BMW makes a car that has square wheels and needs to have everyone install round wheels so the fucking thing works you can’t blame a company for making wheels.
It’s a Microsoft problem through and through.
Your counter to the BMW Drunk driver example didn’t address drunk driving in volvos, toyotas, fords… you just introduced a variable that your upset with. BMW’s having weird wheels has nothing to do with Drunk Driving incidents.
Again your focused on the wrong thing, this story is a warning about supply chain issues.
Your just memeing on the hate for windows.
Have you never seen a DNS outage, a ansible outage, a terraform outage, a RADIUS outage, a database schema change outage, a router firmware update outage?
Again, you’re talking about something I am not. I am talking about THIS problem, right here, that is categorically a windows problem, in that it’s not on the linux kernel stack, or mac. How is this NOT a windows problem??
The fault seems to be 90/10 CS, MS.
MS allegedly pushed a bad update. Ok, it happens. Crowdstrike’s initial statement seems to be blaming that.
CS software csagent.sys took exception to this and royally shit the bed, disabling the entire computer. I don’t think it should EVER do that, so the weight of blame must lie with them.
The really problematic part is, of course, the need to manually remediate these machines. I’ve just spent the morning of my day off doing just that. Thanks, Crowdstrike.
EDIT: Turns out it was 100% Crowdstrike, and the update was theirs. The initial press release from CS seemed to be blaming Microsoft for an update, but that now looks to be misleading.
It is on the sense that Windows admins are the ones that like to buy this kind of shit and use it. It’s not on the sense that Windows was broken somehow.
I’ve just spent the past 6 hours booting into safe mode and deleting crowd strike files on servers.
Feel you there. 4 hours here. All of them cloud instances whereby getting acces to the actual console isn’t as easy as it should be, and trying to hit F8 to get the menu to get into safe mode can take a very long time.
Ha! Yes. Same issue. Clicking Reset in vSphere and then quickly switching tabs to hold down F8 has been a ball ache to say the least!
What I usually do is set next boot to BIOS so I have time to get into the console and do whatever.
Also instead of using a browser, I prefer to connect vmware Workstation to vCenter so all the consoles insta open in their own tabs in the workspace.
Just go into settings and add a boot delay, then set it back when you’re done.
Can’t you automate it?
Since it has to happen in windows safe mode it seems to be very hard to automate the process. I haven’t seen a solution yet.
Sadly not. Windows doesn’t boot. You can boot it into safe mode with networking, at which point maybe with anaible we could login to delete the file but since it’s still manual work to get windows into safe mode there’s not much point
It is theoretically automatable, but on bare metal it requires having hardware that’s not normally just sitting in every data centre, so it would still require someone to go and plug something into each machine.
On VMs it’s more feasible, but on those VMs most people are probably just mounting the disk images and deleting the bad file to begin with.
I guess it depends on numbers too. We had 200 to work on. If you’re talking hundreds more than looking at automation would be a better solution. In our scenario it was just easier to throw engineers at it. I honestly thought at first this was my weekend gone but we got through them easily in the end.
The real problem with VM setups is that the host system might have crashed too
That’s hell of a strike to the crowd
Crowdstrikeout
Crowd II: The Struckening
Crowdstrike already killed some Linux machines. Let’s not pretend Windows is at fault here or Linux is magically better in this area. No one is immune from software that can run as a kernel module going bad.
But, my superiority!
Every system has its faults. And I’m still going to dogpile the system with the most faults. But hell Microsoft did buy GitHub, Halo, MineCraft, and a million other things they will probably find a way to buy Linux and ruin it for us just like they ruin everything else.
Let’s see, …we are somewhere in between Extend and Extinguish on the roadmap.
Edit: Case & Point, RIP RedHat & IBM and GitHub CoPilot, what a great idea. RIP Atom Editor and probably a million other things. Do we have a KilledByMicrosoft website yet? I hope people in the pharmacy could get their prescriptions or we might have to add peoples names to the list.
None of this has to do with the current outage though.
I hope people in the pharmacy could get their prescriptions or we might have to add peoples names to the list.
Which isn’t Microsoft’s fault. Linux systems have also been taken down by Crowdstrike’s fuck ups in the recent past.
Microsoft has many faults and I’ll criticize them as I please. And if Linux is a culprit in a global outage someday I’ll contemplate criticizing them too.
This “Not Microsoft’s Fault” comes off as white knighting for Muh Billion Dolla Corporation.
Do we really need to SIMP for the company town.
Microsoft, Google, Apple, Amazon and others deserve every ounce of vitrol they earn through their shitty practices. Again I am criticizing them for being shitty not for the particulars of System X vs System Z but for the aftermath.
I get where you are coming from, but this event is pretty much entirely the fault of Crowdstrike and the countless organizations that trusted them. It’s definitely a show of how massive outages are more likely when things are overly centralized and proprietary, and managed by big, shitty, profit driven organizations. Since crowdstrike operates in kernel space, it doesn’t matter which operating system it’s on, it can break it if it does something stupid. In fact they managed to break some redhat machines not too long ago, and some Debian machines not long before that. It’s just the impact wasn’t as far reaching as this recent utter fuckup, just because fewer critical machines were affected, so we didn’t hear about those smaller fuckups in the news.
Yes, thank you, exactly. The centralized model has its benefits but it also can act as a single point of failure.
If I was going to analyze from an engineering perspective I would focus on when these inevitable events occur due to human error do we have adequate tools to roll back updates? Do we snapshot OS drives before updates? Is there adequate Safe Mode or Fallback Tools to diagnose which files are offending in order to allow the user to remove them.
In my view the windows user isn’t dignified to have the skills or intelligence needed to workaround a “setback” issue like the one yesterday.
It doesn’t help that NTFS is missing modern capabilities, or that there isn’t easy to use DIFF for the layman to understand which files were added to the filesystem that may be causing the breakage.
To be fair though even with those pot holes filled the entire design paradigm of Windows and a proprietary platform is part of the problem. Software is not broken up into package modules that can be assembled into a functioning system it is encumbered with “anti-piracy” boogie man where the software treats the user as an enemy and is designed to break.
Linux isn’t like that. I’ve cloned many distro drives and swapped them into new machines and with 1 or 2 tweaks they JustWork
I see many people on the net defending Microsoft as blameless for technical reasons.
My criticisms were that Microsoft just sucks as you interpreted correctly and offered a eloquent summary. Thank You.
Where I think the entire conversation should move is –
What are the design flaws that allowed this to happen?
“More Rust & Less C” I see some people suggest as this was allegedly a null pointer issue.
And is Windows Broken By Design? My opinion answer - Yes.
(Okay, and what to do about it before the next billion dollars is lost. I would think critical infrastructure should have a model similar to NixOS in immutability but that’s just my opinion.)
Windows does have a fallback mode called safe mode and that’s exactly what’s being used to fix this utter mess.
Package management isn’t going to save you from this as it didn’t save the Linux systems affected last time. It didn’t stop Arch Linux from failing to boot after a Grub update either.
Windows also has drive cloning tools, that isn’t unique to Linux.
NixOS isn’t immutable. It’s not an a/b root system and / isn’t read only. Rather it’s what’s known as reproducible. I am not convinced NixOS would make this any easier either given how simple the fix was. Funnily enough though tools exist called ansible and puppet for configuring systems in repeatable ways that apply to both other Linux systems, Windows systems, and even macOS.
There are like one or two valid points in this whole comment and the rest is pretty much falsehoods and misconceptions.
Edit: Forgot to mention tools exist to make Windows immutable as well. So that is an option.
Windows does have a fallback mode called safe mode and that’s exactly what’s being used to fix this utter mess.
The other fix was reboot your Windows computer at least 15 times.
Package management isn’t going to save you from this as it didn’t save the Linux systems affected last time. It didn’t stop Arch Linux from failing to boot after a Grub update either.
Not everyone was affected though :
How come not everyone was impacted?
Prior to the most recent version, grub only registered the fwsetup if detected support. If your machine detected support, you would have had the fwsetup command registered and the failure wouldn’t occur.
Except they haven’t done anything shitty this time. What you are doing would be a bit like claiming the Nazis are responsible for micro plastics. Like yeah Nazis are shit but making false allegations is just giving their defenders something to throw in your face. It makes you, and everyone who is critical of Microsoft look dumb. How about you criticize the company that actually screwed up? They are also a multi-billion dollar company, yet you aren’t blaming them for something that is clearly their fault.
Sure you can criticize as much as you want but if you are wrong in your criticism it just damages all of your criticism over all.
In my opinion it is important to state facts not fiction. This was not Microsoft’s fault, no matter how much you hate Microsoft it still wasn’t there fault and saying that is was is incorrect and doesn’t solve the issue.
Well said, that’s one of the points I have been trying to get across.
Also fyi Red Hat and IBM are still around and aren’t really a force for good anyway. Stop SIMPing for large companies.
Hilarious. I am sure that, out of principle, you have stopped using all the software that Red Hat contributes to your distribution.
If it is ok with you, I am not going to define my morality in terms of corporate interest. They are not my friends but I do not believe that shutting on their contributions does much for me either.
I am not shitting on their contributions. All I am saying is that as a large company they aren’t anymore my friend than Microsoft. Generally they still exist and make contributions. Microsoft didn’t kill them like the person I am replying to is insinuating.
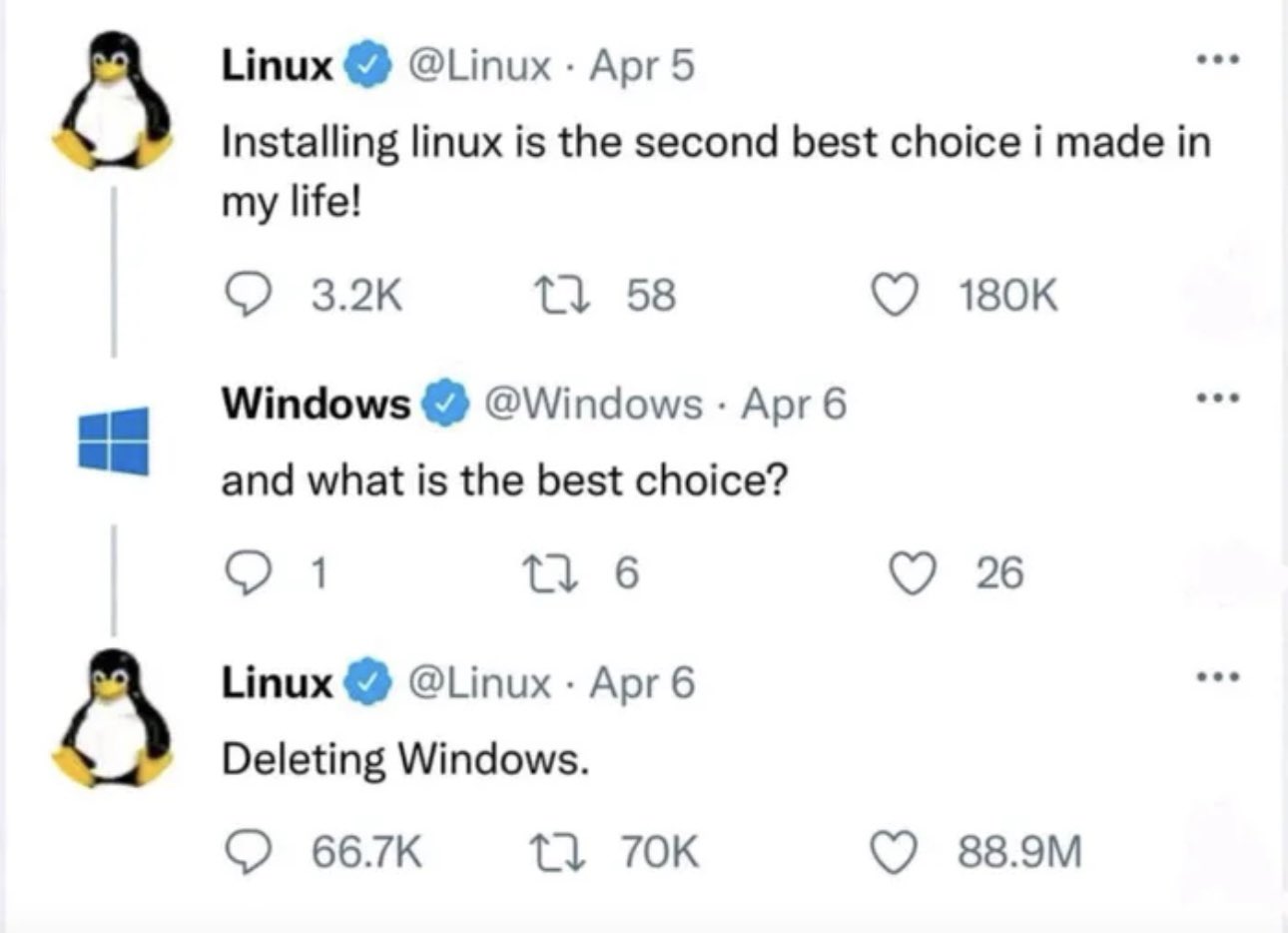
I work in hospitality and our systems are completely down. No POS, no card processing, no reservations, we’re completely f’ked.
Our only saving grace is the fact that we are in a remote location and we have power outages frequently. So operating without a POS is semi-normal for us.
I’ve worked with POS systems my whole career and I still can’t help think Piece Of Shit whenever I see it
I am born too late to understand what Y2K problem was, this (the result) might be what people thought could happen.
Yep pretty much but on a larger scale.
1st please do not believe the bull that there was no problem. Many folks like me were paid to fix it before it was an issue. So other than a few companies, few saw the result, not because it did not exist. But because we were warned. People make jokes about the over panic. But if that had not happened, it would hav been years to fix, not days. Because without the panic, most corporations would have ignored it. Honestly, the panic scared shareholders. So boards of directors had to get experts to confirm the systems were compliant. And so much dependent crap was found running it was insane.
But the exaggerations of planes falling out of the sky etc. Was also bull. Most systems would have failed but BSOD would be rare, but code would crash and some works with errors shutting it down cleanly, some undiscovered until a short while later. As accounting or other errors showed up.
As other have said. The issue was that since the 1960s, computers were set up to treat years as 2 digits. So had no expectation to handle 2000 other than assume it was 1900. While from the early 90s most systems were built with ways to adapt to it. Not all were, as many were only developing top layer stuff. And many libraries etc had not been checked for this issue. Huge amounts of the infra of the world’s IT ran on legacy systems. Especially in the financial sector where I worked at the time.
The internet was a fairly new thing. So often stuff had been running for decades with no one needing to change it. Or having any real knowledge of how it was coded. So folks like me were forced to hunt through code or often replace systems that were badly documented or more often not at all.
A lot of modern software development practices grew out of discovering what a fucking mess can grow if people accept an “if it ain’t broke, don’t touch it” mentality.
Was there patching systems and testing they survived the rollover months before it happened.
One software managed the rollover. But failed the year after. They had quickly coded in an explicit exception for 00. But then promptly forgot to fix it properly!.
Kinda I guess. It was about clocks rolling over from 1999 to 2000 and causing a buffer overflow that would supposedly crash all systems everywhere causing the country to come to a hault.
And it was okay because a lot of people worked really really hard to make it be okay.
Most old systems used two digits for years. The year would go from 99 to 0. Any software doing a date comparison will get a garbage result. If a task needs to be run every 5 minutes, what will the software do if that task was last run 99 years from now? It will not work properly.
Governments and businesses spent lots of money and time patching critical systems to handle the date change. The media made a circus out of it, but when the year rolled over, everything was fine.
Also a lot of people were “on call” to handle any problems when the year changed, so the few problem that had passed unnoticed when doing the fixed and did pop up when the year changed, got solved a lot faster than they normally would.
One program I tested went from (31,12,99) to (01,01,100). Its front end formatted the date and added the century, so it showed 1 January 2000 as 01/01/19100
That wasn’t fixed. The fault didn’t affect processing (the years were wrong but had the correct offset between them) and was only visible to internal users, and also that system was expected to be retired in 2004
We also got the worst version of Windows ever, ME. Tho maybe with all the BS they’ve done with 11 that might change.
I’m not sure I’d stick to calling it the worst version “ever” since MS is trying really hard to out do themselves.
I’d use ME before the adware that is the current version. It wasn’t that bad, it was just Win98 with some visual slop on top that crashed slightly more often.
Millennium Editions ruin everything!! 🤬
Y2K was going to be the end of civilisation. This was basically done by the time I woke up today.
Most people are completely oblivious because it only affects people using crowdstrike, which practically excludes general consumers.
I just had an Amazon package delayed for a week it says. It doesn’t name names but…
A small number of deliveries may arrive a day later than anticipated due to a third-party technology outage.
I love how everyone understands the issue wrong. It’s not about being on Windows or Linux. It’s about the ecosystem that is common place and people are used to on Windows or Linux. On windows it’s accepted that every stupid anticheat can drop its filthy paws into ring 0 and normies don’t mind. Linux has a fostered a less clueless community, but ultimately it’s a reminder to keep vigilant and strive for pure and well documented open source with the correct permissions.
BSODs won’t come from userspace software
While that is true, it makes sense for antivirus/edr software to run in kernelspace. This is a fuck-up of a giant company that sells very expensive software. I wholeheartedly agree with your sentiment, but I mostly see this as a cautionary tale against putting excessive trust and power in the hands of one organization/company.
Imagine if this was actually malicious instead of the product of incompetence, and the update instead ran ransomware.
If it was malicious it wouldn’t have had the reach a trusted platform would. That is what made the xz exploit so scary was the reach and the malicious attempt.
I like open source software but that’s one big benefit of proprietary software. Not all proprietary software is bad. We should recognize the ones doing their best to avoid anti consumer practices and genuinely try to serve their customers needs to the best of their abilities.
Crowdstrike does have linux and mac version. Not sure who runs it
I deployed it for my last employer on our linux environment. My buddies who still work there said Linux was fine while they had to help the windows Admins fix their hosts.
That’s precisely why I didn’t blame windows in my post, but the windows-consumer mentality of “yeah install with privileges, shove genshin impact into ring 0 why not”
Linux can have the same issue. We have to keep the culture on our side here vigilant and pure near the kernel.
Am on holiday this week - called in to help deal with this shit show :(
Don’t worry, George Kurtz (crowdstrike CEO) is unavailable today. He’s got racing to do #04 https://www.gt-world-challenge-america.com/event/95/virginia-international-raceway
i hope you get overtime!
Would you really be paying for Crowdstrike for use at home?
I wanted to share the article with friends and copy a part of the text I wanted to draw attention to but the asshole site has selection disabled. Now I will not do that and timesnownews can go fuck themselves
It is annoying. Some possible solutions:
On desktop: Using Shift + ALT you often can overrule this and select text anyway.
On mobile: Using the reader mode or the Print preview often works. It does for me on this website.
The firefox reader mode button doesn’t show up for me on that site. I wonder if its just a poor site or if they are intentionally trying to break it.
Could be both. You can enforce it: https://addons.mozilla.org/en-US/firefox/addon/activate-reader-view/
heres the entire article
Latest Crowdstrike Update Issue: Many Windows users are experiencing Blue Screen of Death (BSOD) errors due to a recent CrowdStrike update. The issue affects various sensor versions, and CrowdStrike has acknowledged the problem and is investigating the cause, as stated in a pinned message on the company’s forum.
Who Have Been Affected
Australian banks, airlines, and TV broadcasters first reported the issue, which quickly spread to Europe as businesses began their workday. UK broadcaster Sky News couldn’t air its morning news bulletins, while Ryanair experienced IT issues affecting flight departures. In the US, the Federal Aviation Administration grounded all Delta, United, and American Airlines flights due to communication problems, and Berlin airport warned of travel delays from technical issues.
In India too, numerous IT organisations were reporting in issues with company-wide. Akasa Airlines and Spicejet experienced technical issues affecting online services. Akasa Airlines’ booking and check-in systems were down at Mumbai and Delhi airports due to service provider infrastructure issues, prompting manual check-in and boarding. Passengers were advised to arrive early, and the airline assured swift resolution. Spicejet also faced problems updating flight disruptions, actively working to fix the issue. Both airlines apologized for the inconvenience caused and promised updates as soon as the problems were resolved.
Crowdstrike’s Response
CrowdStrike acknowledged the problem, linked to their Falcon sensor, and reverted the faulty update. However, affected machines still require manual intervention. IT admins are resorting to booting into safe mode and deleting specific system files, a cumbersome process for cloud-based servers and remote laptops. Reports from IT professionals on Reddit highlight the severity, with entire companies offline and many devices stuck in boot loops. The outage underscores the vulnerability of interconnected systems and the critical need for robust cybersecurity solutions. IT teams worldwide face a long and challenging day to resolve the issues and restore normal operations.
What to Expect:-A Technical Alert (TA) detailing the problem and potential workarounds is expected to be published shortly by CrowdStrike.
-The forum thread will remain pinned to provide users with easy access to updates and information.What Users Should Do:
-Hold off on troubleshooting: Avoid attempting to fix the issue yourself until the official Technical Alert is released.
-Monitor the pinned thread: This thread will be updated with the latest information, including the TA and any temporary solutions.
-Be patient: Resolving software conflicts can take time. CrowdStrike is working on a solution, and updates will be posted as soon as they become available.In an automated reply from Crowdstrike, the company had stated: CrowdStrike is aware of reports of crashes on Windows hosts related to the Falcon Sensor. Symptoms include hosts experiencing a blue screen error related to the Falcon Sensor. The course of current action will be - our Engineering teams are actively working to resolve this issue and there is no need to open a support ticket. Status updates will be posted as we have more information to share, including when the issue is resolved.
For Users Experiencing BSODs:
If you’re encountering BSOD errors after a recent CrowdStrike update, you’re not alone. This appears to be a widespread issue. The upcoming Technical Alert will likely provide specific details on affected CrowdStrike sensor versions and potential workarounds while a permanent fix is developed.
If you have urgent questions or concerns, consider contacting CrowdStrike support directly.If you have urgent questions or concerns, consider contacting CrowdStrike support directly.
Something tells me that isn’t going to provide the comfort it was meant to.
















