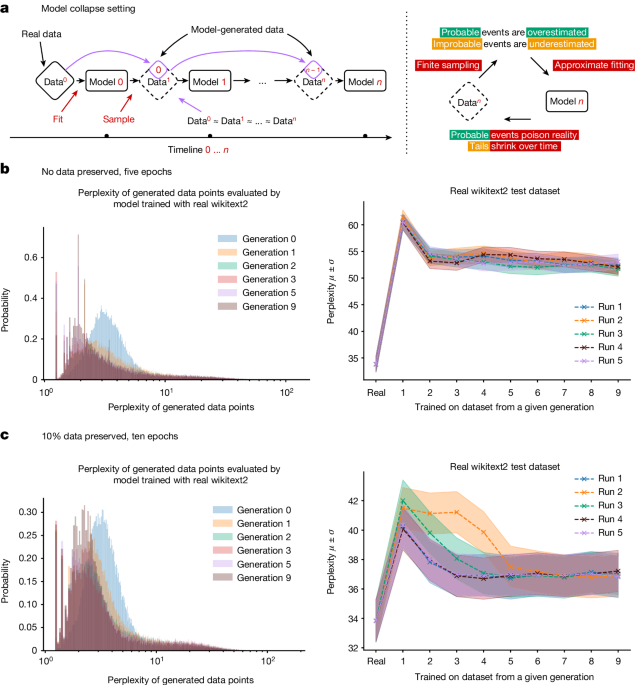
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
You have to pretty much intentionally give it enough synthetic data to wreck it. OpenAI and Anthropic train their models on generated data to improve them. As long as there’s supervision during training, which there always will be, this isn’t really a problem.
Well… Its built on statistics and statistical inference will return to the mean eventually. If all it ever gets to train on is closer and closer to the mean, there will be nothing left to work with. It will all be the average…

Yep. It leads to a positive feedback loop. They just continue to self-reinforce whatever came out before.
And with increasing amounts of the internet being polluted with AI text output…
… AI inbreeding.
hapsburgGPT
We call it the GRRM model.
In the USA, they call it the AlaLlama model.
GPTargaryen
What about the Grrr! model after that astoundingly XD So Random! thing from Invader Zim?
He’s an android or robot, right?
AInbreeding
That seems so obviously predictable.
To be fair this doesn’t sound much different than your average human using the internet.
2024, Reverse Turing Test Challenge:
Can an LLM AI differentiate between human input and LLM AI input?
You have to pretty much intentionally give it enough synthetic data to wreck it. OpenAI and Anthropic train their models on generated data to improve them. As long as there’s supervision during training, which there always will be, this isn’t really a problem.
https://openai.com/index/prover-verifier-games-improve-legibility/
https://www.anthropic.com/research/claude-character
Well… Its built on statistics and statistical inference will return to the mean eventually. If all it ever gets to train on is closer and closer to the mean, there will be nothing left to work with. It will all be the average…