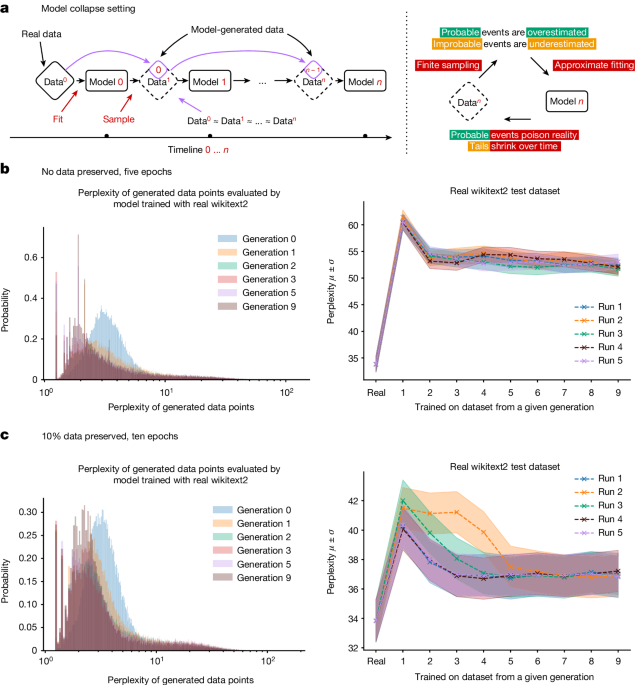
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
This has been obvious for a while to those of us using GitHub Copilot for programming. Start a function, and then just keep hitting tab to let it autotype based on what it already wrote. It quickly devolves into strange and random bullshit. You gotta babysit it.

This has been obvious for a while to those of us using GitHub Copilot for programming. Start a function, and then just keep hitting tab to let it autotype based on what it already wrote. It quickly devolves into strange and random bullshit. You gotta babysit it.
very unlikely to stem from model collapse. why would they use a worse model? it’s probably because they neutered it or gave it less resources.
It learns from your own code as you type so it can offer more relevant suggestions unlike the web-based LLMs. So you can make it feed back on itself.
Where did you learn to write such shitty code?
I learned it from watching you!
Same thing with Stable Diffusion if you’ve ever used a generated image as an input and repeated the same prompt. You basically get a deep-fried copy.
img2img is not “training” the model. Completely different process.
Oh yeah, you’re right. It’s both degradation in some way, but through entirely different causes.