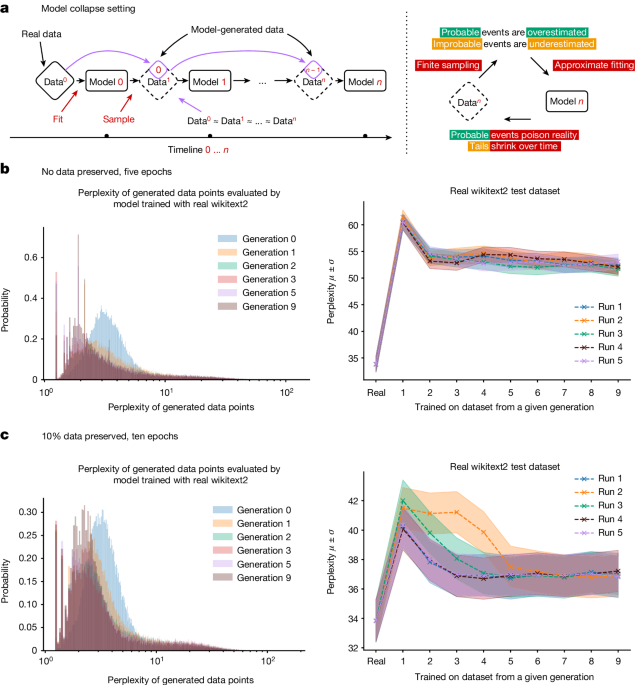
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
It’s already happening. A quote from Andrej Karpathy :
Turns out that LLMs learn a lot better and faster from educational
content as well. This is partly because the average Common Crawl article
(internet pages) is not of very high value and distracts the training,
packing in too much irrelevant information. The average webpage on the
internet is so random and terrible it’s not even clear how prior LLMs
learn anything at all.

It’s already happening. A quote from Andrej Karpathy :