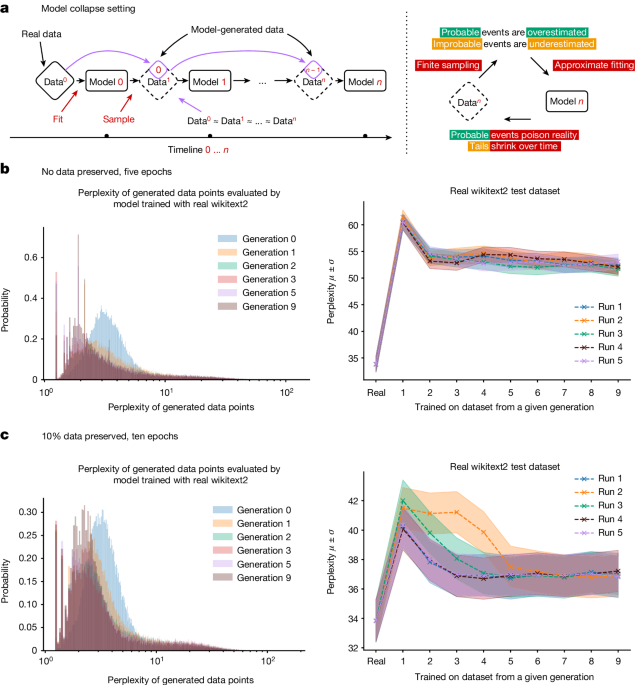
Analysis shows that indiscriminately training generative artificial intelligence on real and generated content, usually done by scraping data from the Internet, can lead to a collapse in the ability of the models to generate diverse high-quality output.
You realize that those “billions of dollars” have actually resulted in a solution to this? “Model collapse” has been known about for a long time and further research figured out how to avoid it. Modern LLMs actually turn out better when they’re trained on well-crafted and well-curated synthetic data.
Honestly, everyone seems to assume that machine learning researchers are simpletons who’ve never used a photocopier before.

You realize that those “billions of dollars” have actually resulted in a solution to this? “Model collapse” has been known about for a long time and further research figured out how to avoid it. Modern LLMs actually turn out better when they’re trained on well-crafted and well-curated synthetic data.
Honestly, everyone seems to assume that machine learning researchers are simpletons who’ve never used a photocopier before.